从理解大模型到本地部署你的第一个私有 ChatBot,一篇文章带你打通全流程。
一、认识大模型:从概念到分类
1.1 什么是大模型?
大模型(Large Language Model, LLM)是通过在海量文本数据上训练出来的超大型人工智能程序。你可以把它想象成一个"博览群书的超级大脑"——它学习了互联网上几乎所有的公开知识,从而获得了强大的语言理解、生成和推理能力。
1.2 大模型的四大类别
当前主流的大模型按处理的数据模态可分为四类:
| 类别 | 核心能力 | 代表模型 |
|---|---|---|
| 自然语言处理(NLP) | 文本生成、理解、翻译 | GPT-4、BERT、T5、DeepSeek |
| 计算机视觉(CV) | 图像分类、目标检测、图像生成 | Stable Diffusion、ViT、DALL·E、CLIP |
| 语音模型 | 语音识别(ASR)、语音合成(TTS) | Whisper、WaveNet、讯飞星火 |
| 多模态模型 | 同时处理文本、图像、音频等多种数据 | GPT-4V、Flamingo、BLIP |
NLP模型专注于文本任务,如DeepSeek、 GPT 系列(OpenAI)、BERT(Google)、T5(Google)。
计算机视觉(CV)模型通过大规模数据和复杂架构,实现对图像和视频的深度理解,如 Stable Diffusion、DALL·E、CLIP 等。

语音模型基于深度学习,处理语音识别、合成、翻译等任务。代表模型包括 Whisper(OpenAI)、WaveNet(DeepMind)、讯飞星火等。

多模态模型能够同时处理文本、图像、音频、视频等多种数据,核心在于跨模态融合。代表模型:GPT-4、Flamingo、BLIP、KOSMOS。
1.3 基础模型(Foundation Model)架构
下图展示了一个基础模型如何通过训练处理不同类型的数据,并执行多种任务:
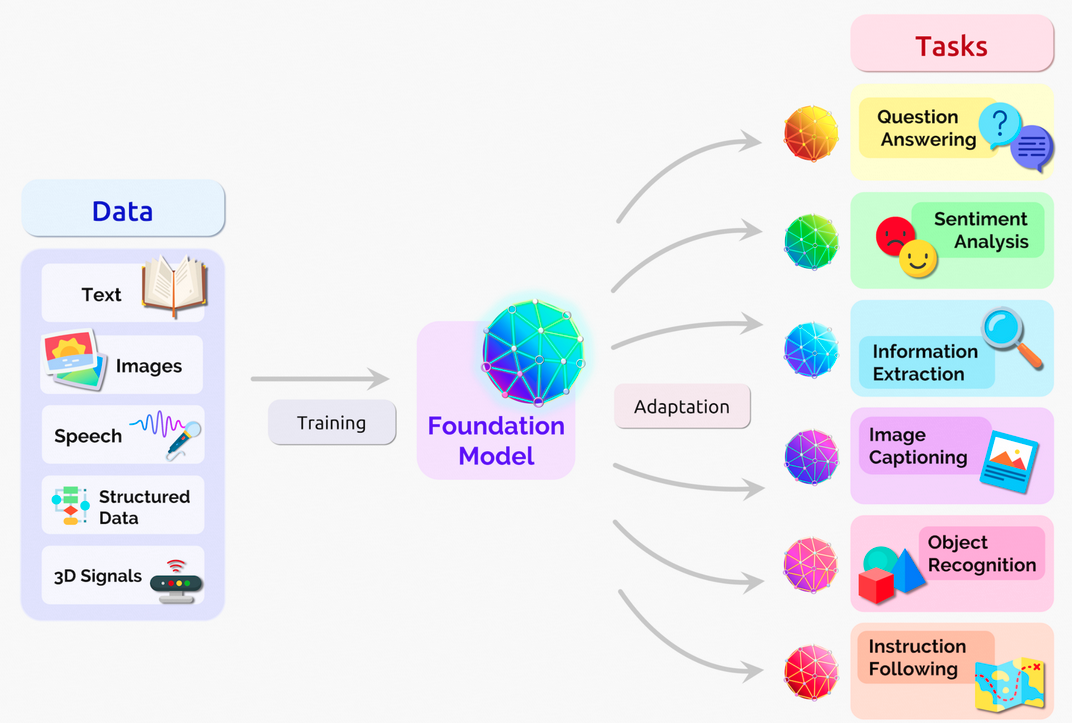
数据(Data):文本、图像、语音、结构化数据、3D信号 训练(Training):使用多模态数据对基础模型进行训练 适应(Adaptation):针对特定任务进行优化 任务(Tasks):问答、情感分析、信息提取、图像描述、物体识别、指令遵循
1.4 大模型的典型应用场景
- 智能客服:7×24 小时在线问答,目前最广泛的商业落地场景
- 文本生成:文章、代码、营销文案、报告撰写
- 机器翻译:高质量多语言实时翻译
- 图像识别:自动驾驶、安防监控、医疗影像分析
- 知识问答:企业内部知识库检索与技术支持

二、为什么企业需要私有化部署?
随着 AI 普及,数据安全问题日益凸显。三星员工曾因使用 ChatGPT 处理工作,导致半导体设备源码、产品良率等核心机密泄露,引发全球企业对 AI 数据安全的警惕。
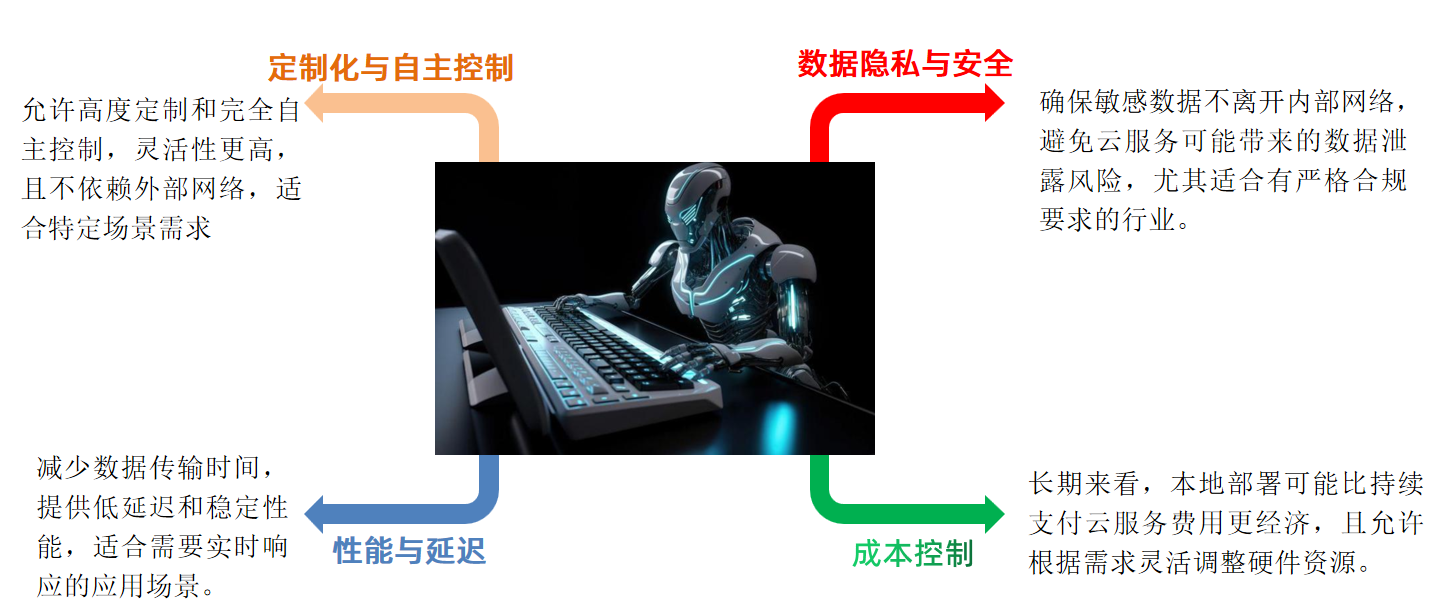
私有化部署大模型的核心价值在于:
- 数据隐私与安全:敏感数据完全留在内部网络,杜绝云端泄露风险,满足金融、医疗、政务等行业的严格合规要求。
- 定制化与自主控制:允许高度定制和完全自主控制,灵活性更高,且不依赖外部网络,适合特定业务场景需求。
- 性能与低延迟:减少数据传输时间,提供低延迟和稳定性能,适合需要实时响应的应用场景。
- 长期成本控制:长期来看,本地部署可能比持续支付云服务 API 费用更经济,且允许根据需求灵活调整硬件资源。
典型案例:三星员工使用 ChatGPT 泄露公司机密,包括半导体设备测量源代码、产品良率程序代码、内部会议纪要等。
三、私有化方案选型:Ollama vs LM Studio
目前主流的本地大模型运行方案主要有两个:Ollama 和 LM Studio。
| 维度 | Ollama | LM Studio |
|---|---|---|
| 定位 | 开源的本地 LLM 运行框架 | 闭源的本地模型工作站 |
| 特点 | 轻量、开源、API 友好、社区活跃 | 功能全面、UI 精美、适合非技术人员 |
| 适用场景 | 开发测试、企业应用集成、快速原型 | 个人使用、模型训练调试、学术研究 |
| 成本 | 开源免费 | 闭源商业软件 |
| 用户友好性 | 界面化操作,适合不同水平用户 | 友好的用户界面,适合初学者 |
| 资源要求 | 需要一定内存或显存,支持跨平台 | 构建复杂模型需大量计算资源 |
选择建议:如果你是开发者,或者希望将大模型能力集成到自己的应用中,Ollama 是最佳选择。它提供完整的 REST API,支持热加载、跨平台运行,且社区生态极其活跃。
四、Ollama 快速入门
4.1 Ollama 是什么?

Ollama(中文戏称"羊驼")是一款旨在简化大模型本地部署和运行的开源软件。它将模型权重、配置和数据打包为一个统一的 Modelfile,让你无需关注底层实现细节,即可一键运行 Llama、DeepSeek、通义千问等主流模型。
官网:https://ollama.com/
核心优势: - 一站式管理:一键运行 Llama 3、DeepSeek、Qwen 等热门模型 - 热加载模型:无需重启即可切换不同模型 - 资源占用少:支持纯 CPU 推理,对硬件要求友好 - 跨平台支持:Windows、macOS、Linux 全覆盖 - 无复杂依赖:优化推理代码,可在各种硬件上高效运行
4.2 安装 Ollama
支持平台: - Windows:https://ollama.com/download/OllamaSetup.exe - Mac:https://ollama.com/download/Ollama-darwin.zip - Linux:https://ollama.com/download/ollama-linux-amd64
Windows 安装步骤:
- 下载安装包(
OllamaSetup.exe),右键以管理员身份运行 - 点击 Install 完成安装
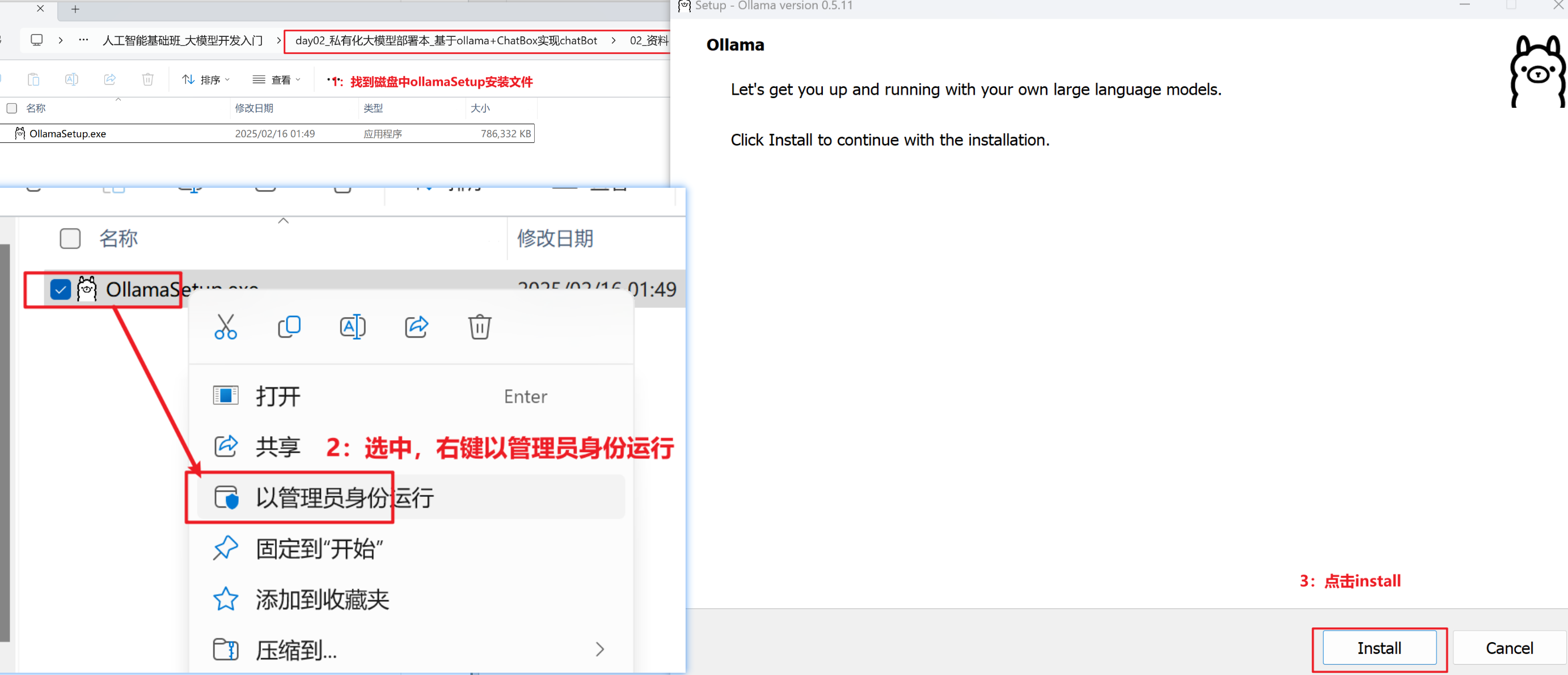
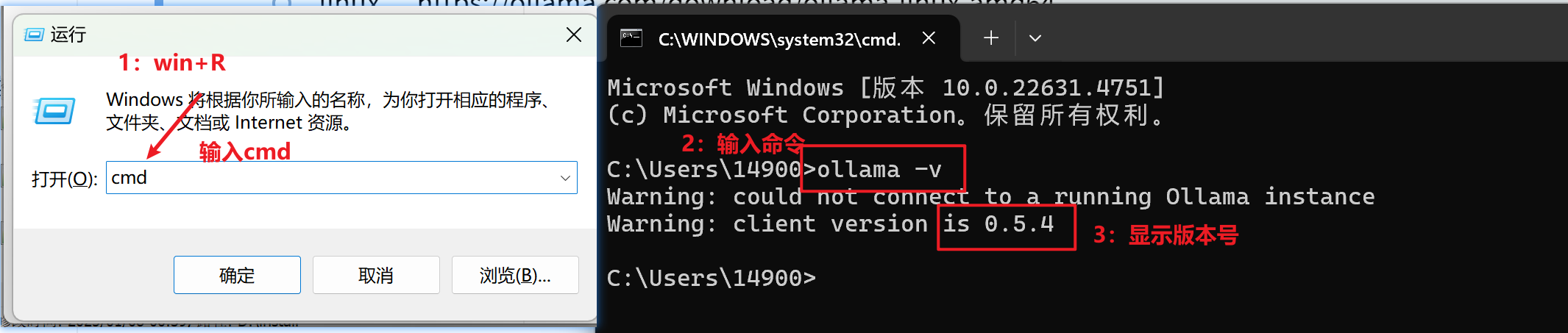
Win + R输入cmd,执行ollama -v验证安装
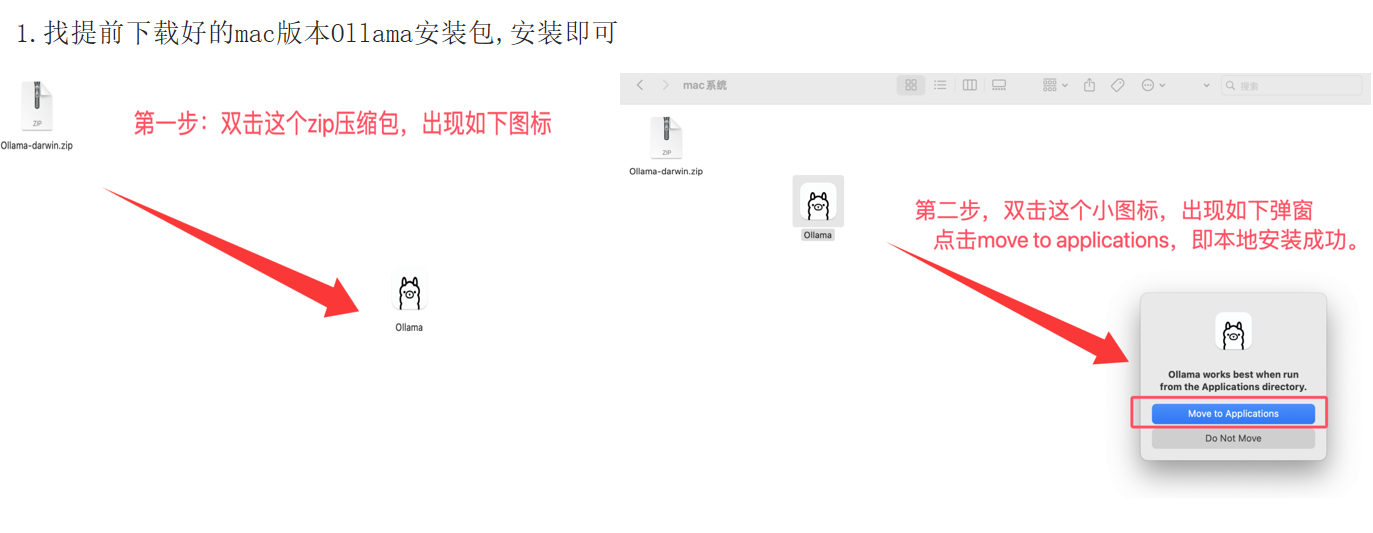
macOS 安装步骤:
- 下载
Ollama-darwin.zip,解压后双击图标 - 点击 "Move to Applications"
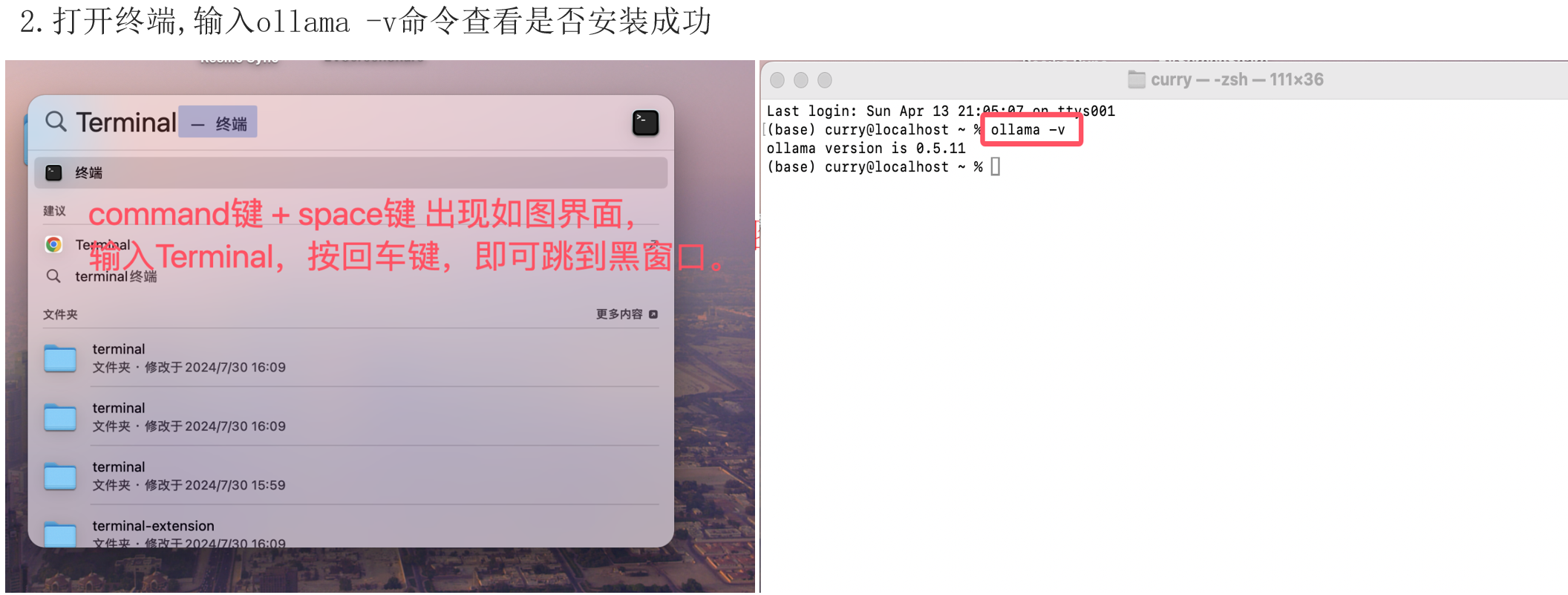
- 打开 Terminal,执行
ollama -v验证
4.3 Ollama 官方模型库
Ollama 支持多种开源模型,涵盖文本生成、代码生成、多模态推理等场景。
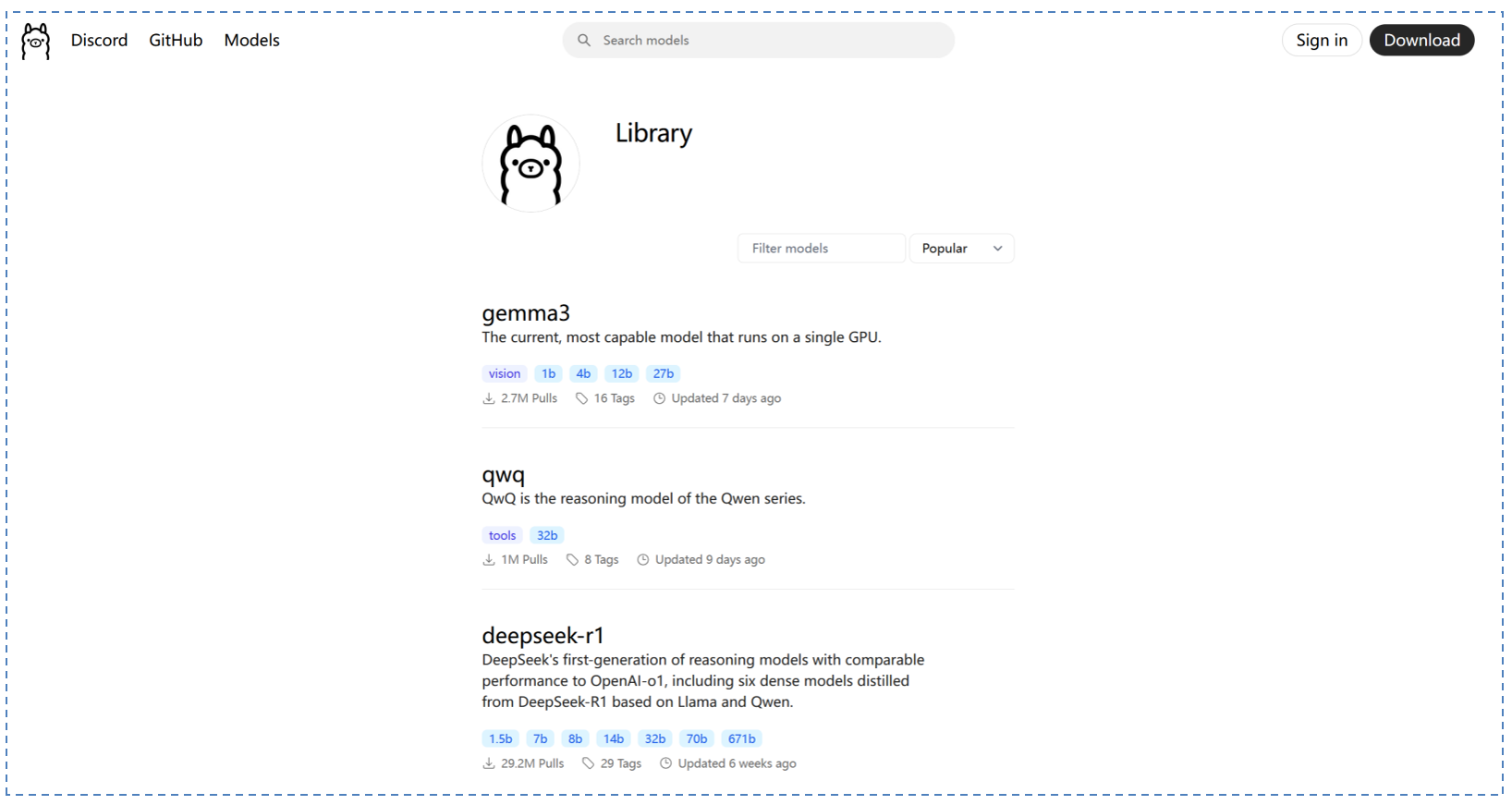
4.4 部署你的第一个大模型
以部署 DeepSeek-R1 为例:
步骤:
1. 访问 https://ollama.com/library 查找模型
2. 选择模型版本(如 1.5b、7b、14b 等)
3. 复制命令 ollama run deepseek-r1:1.5b
4. 在终端粘贴执行
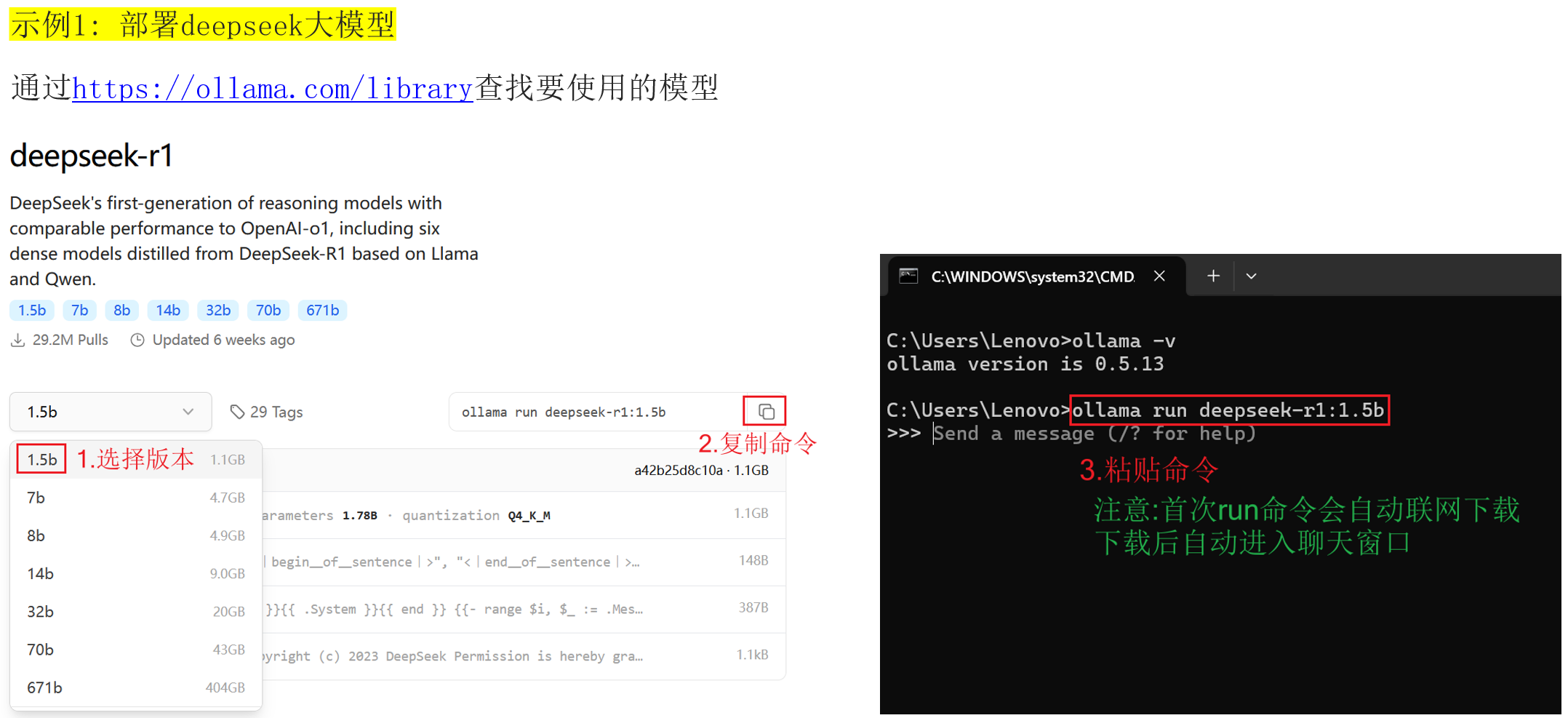
# 部署 1.5B 轻量版(适合入门测试,约1.1GB)
ollama run deepseek-r1:1.5b
# 部署 7B 标准版(需要 4.7GB 空间)
ollama run deepseek-r1:7b
注意:首次运行会自动联网下载模型,下载完成后直接进入对话窗口。
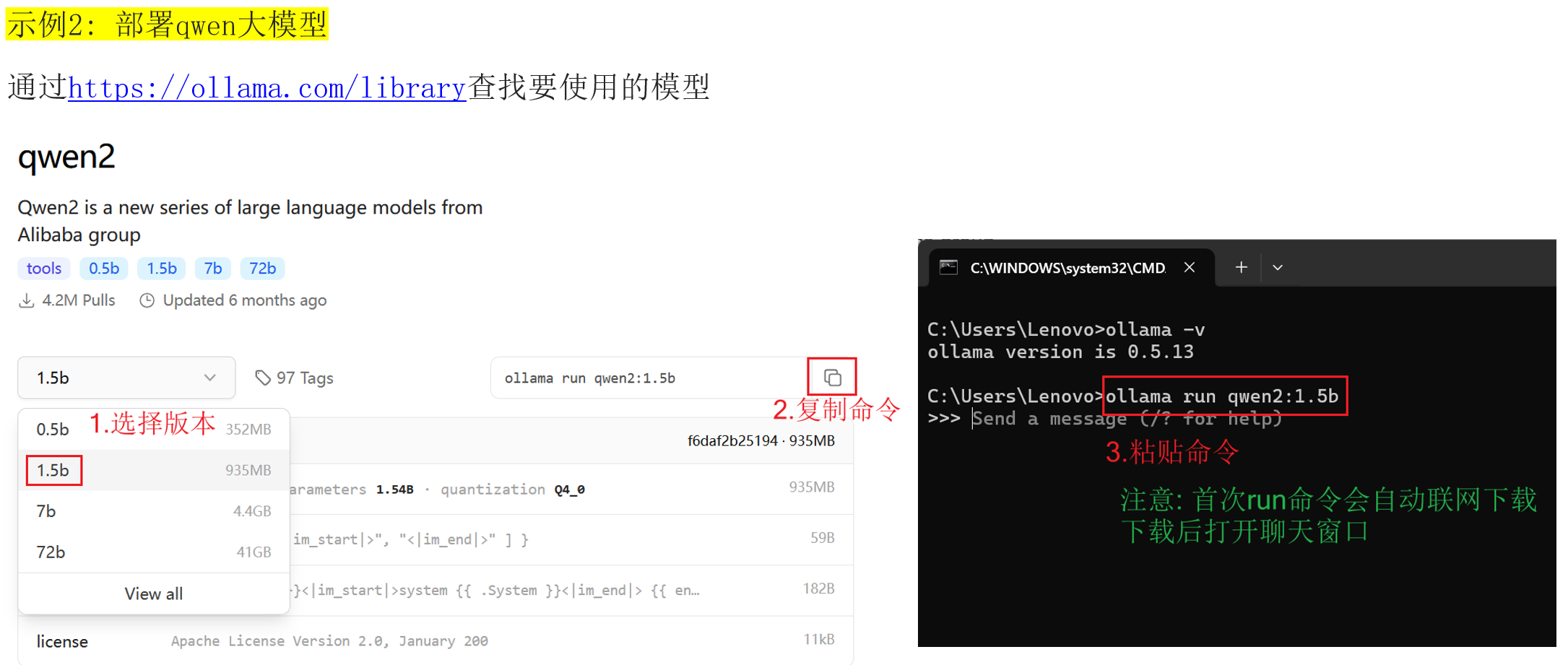
同理,部署阿里通义千问:
ollama run qwen2:1.5b
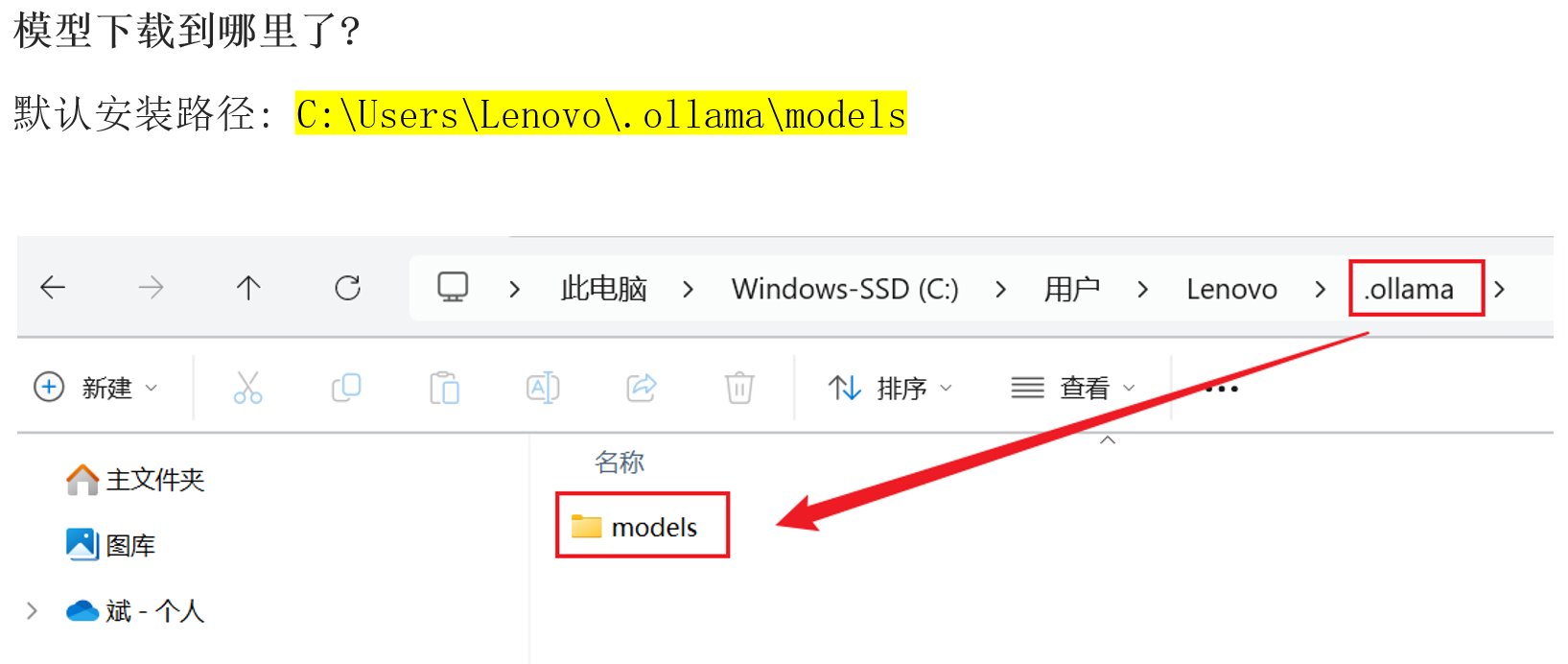
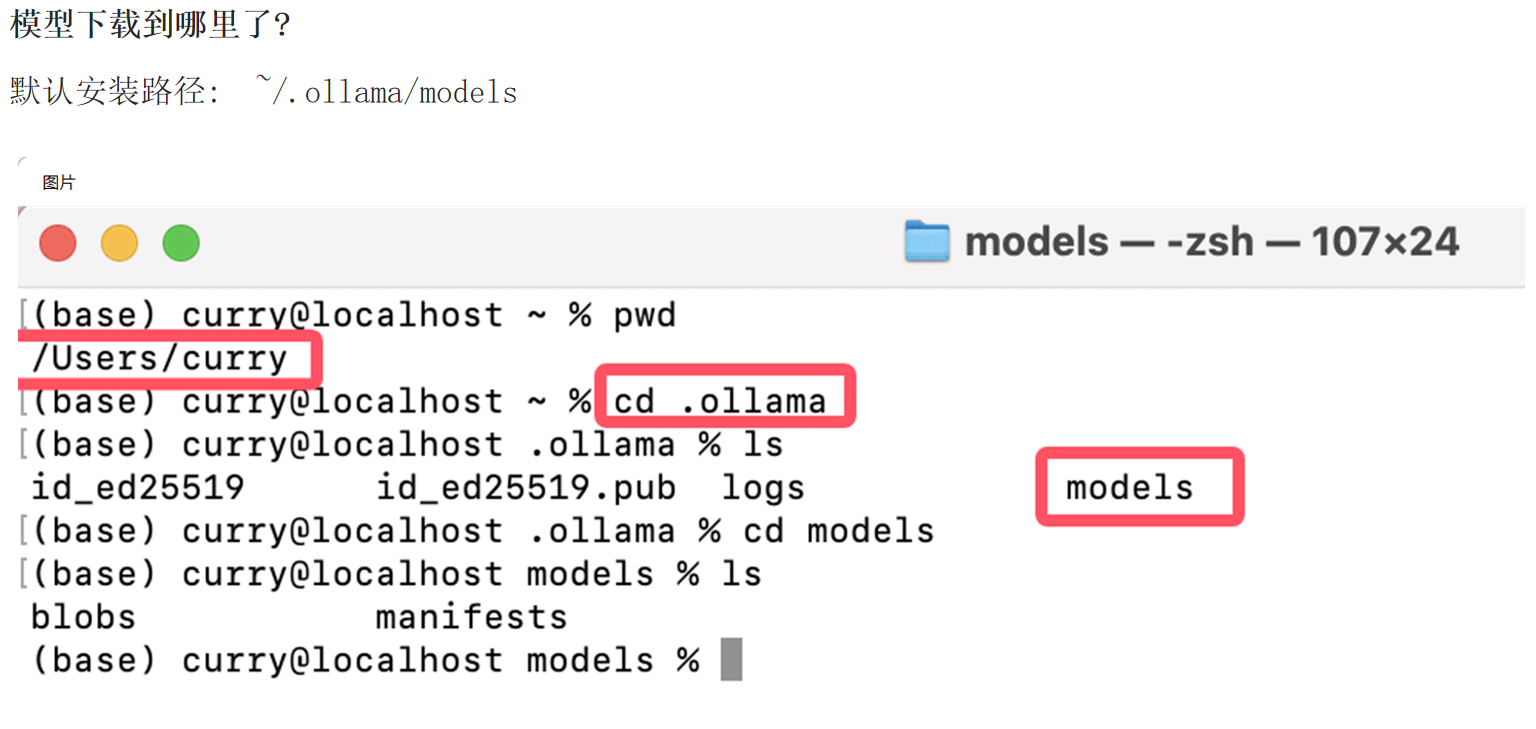
4.5 模型文件存储位置
默认情况下,模型文件存放在以下路径:
- Windows:
C:\Users\<用户名>\.ollama\models - macOS:
~/.ollama/models
修改模型存储位置(解决 C 盘空间不足):
设置系统环境变量 OLLAMA_MODELS 为你自定义的路径:
OLLAMA_MODELS=D:\ollama\models
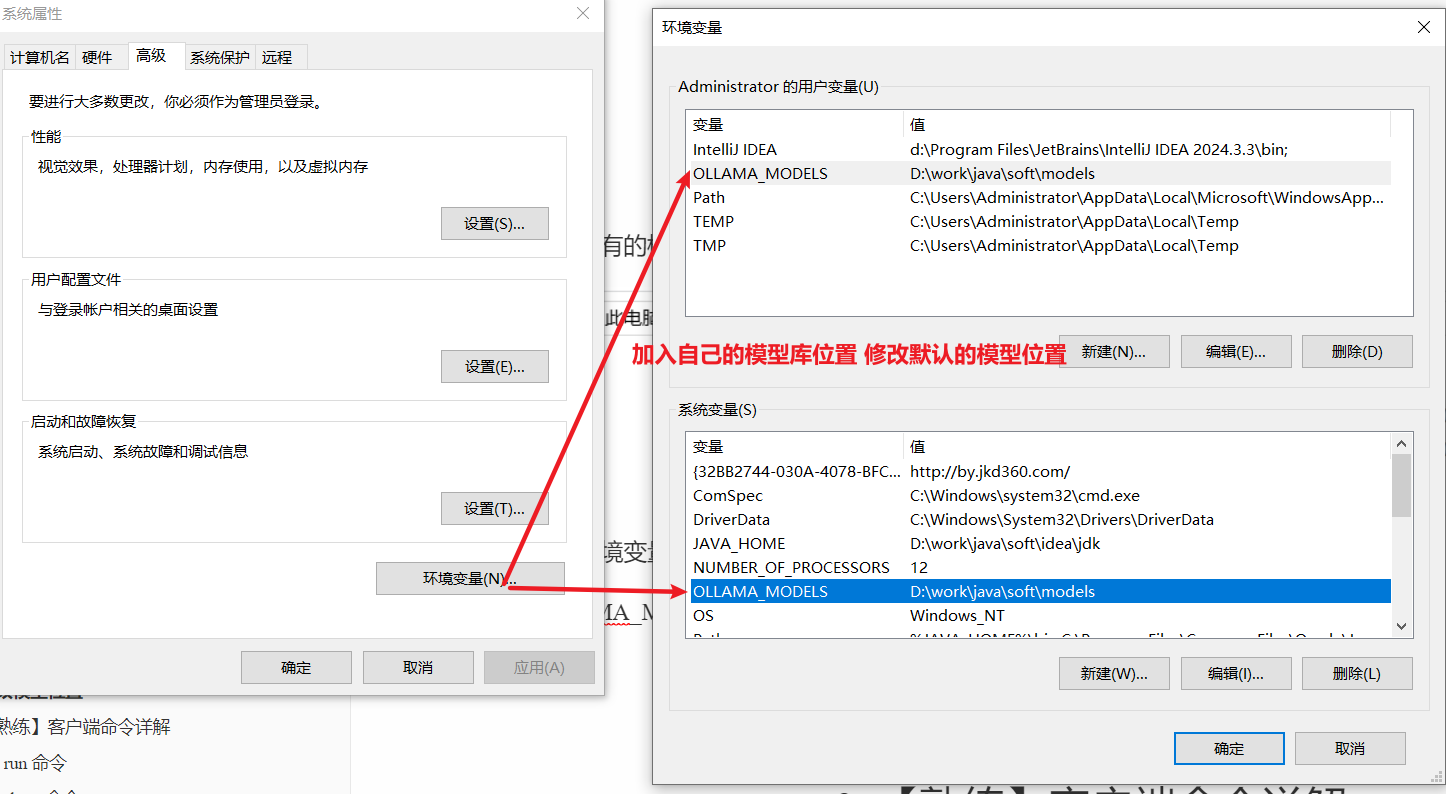
设置完成后重启电脑生效,然后将原 models 文件夹下的 blobs 和 manifests 复制到新目录即可。
五、Ollama 核心命令速查
掌握以下命令,你就能熟练管理本地模型:
| 命令 | 作用 | 示例 |
|---|---|---|
ollama run <模型> |
运行模型(自动下载) | ollama run qwen2:1.5b |
ollama pull <模型> |
仅下载模型不运行 | ollama pull deepseek-r1:7b |
ollama list / ls |
查看已下载的模型列表 | ollama list |
ollama ps |
查看当前运行的模型 | ollama ps |
ollama rm <模型> |
删除本地模型 | ollama rm qwen2:0.5b |
ollama show <模型> |
查看模型详细信息 | ollama show qwen2 --template |
run 命令高阶用法:
# 单次提问模式(不进入交互式对话)
ollama run qwen2:0.5b "请用Python写一个冒泡排序"
# 开启详细统计(查看 Token 消耗和推理速度)
ollama run qwen2:0.5b --verbose
show 命令常用参数:
- --license:查看模型许可信息
- --modelfile:查看模型制作源文件
- --parameters:查看内置参数信息
- --system:查看内置 System 信息
- --template:查看提示词模板
六、对话交互进阶技巧
进入模型对话后,Ollama 提供了一系列内置指令来调整对话行为:
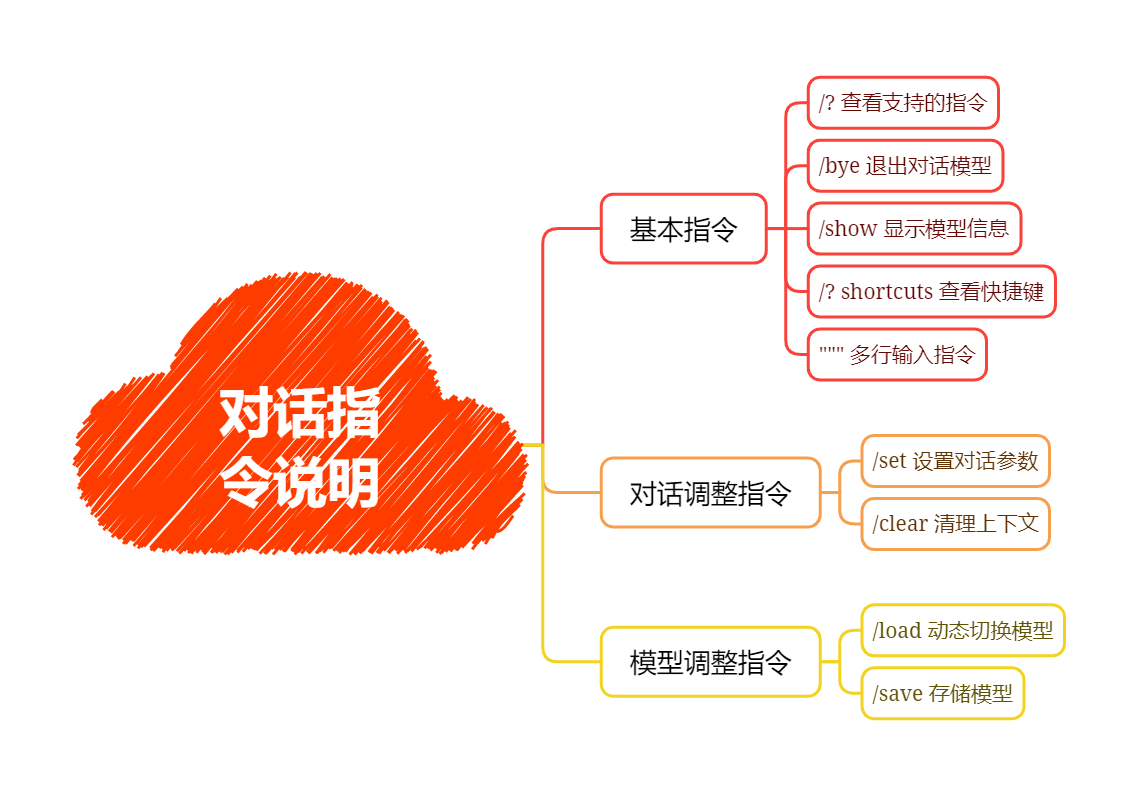
6.1 基础指令
| 指令 | 功能 |
|---|---|
/? |
查看所有支持的指令 |
/bye |
退出对话(快捷键 Ctrl + D) |
/show info |
查看当前模型信息(参数量、量化级别等) |
/show template |
查看模型提示词模板 |
""" |
多行输入模式(输入三个引号后回车,可输入多行内容,再以三个引号结束) |
6.2 对话参数调整(/set)
/set parameter temperature 0.7 # 调整创造性(越低越保守,默认0.8)
/set parameter num_ctx 4096 # 扩大上下文窗口(默认2048)
/set parameter top_k 40 # 控制回答多样性(默认40)
/set parameter top_p 0.9 # 与top_k配合控制多样性(默认0.9)
/set parameter repeat_penalty 1.1 # 重复惩罚强度(默认1.1)
/set format json # 强制输出 JSON 格式
/set noformat # 关闭格式输出
/set verbose # 开启 Token 统计日志
/set quiet # 关闭统计日志
/set history # 开启对话历史
/set nohistory # 关闭上下文记忆(每次提问独立)
6.3 上下文与模型切换
| 指令 | 作用 |
|---|---|
/clear |
清空当前对话上下文(解决"答非所问") |
/load <模型名> |
不退出对话,直接切换其他模型 |
/save <新模型名> |
将当前对话保存为一个新模型 |
实用场景:当你发现模型"跑偏"或上下文混乱时,输入 /clear 即可让模型"失忆",重新开始。
七、通过 API 调用 Ollama(开发者必备)
Ollama 默认提供 HTTP API 服务(端口 11434),这意味着你可以像调用 OpenAI API 一样,在代码中调用本地模型。
7.1 HTTP 基础
- 请求方式:GET(获取资源)、POST(提交数据)
- 常见状态码:200(成功)、404(资源不存在)、500(服务器错误)
- API/接口:访问服务器中指定功能的地址连接
7.2 核心 API 接口
| 方法 | 接口 | 说明 |
|---|---|---|
| POST | /api/chat |
聊天对话(最重要) |
| POST | /api/generate |
内容生成 |
| POST | /api/embeddings |
文本向量化 |
| GET | /api/tags |
查询本地可用模型 |
| GET | /api/ps |
查询运行中的模型 |
| POST | /api/pull |
拉取远程模型 |
| DELETE | /api/delete |
删除本地模型 |
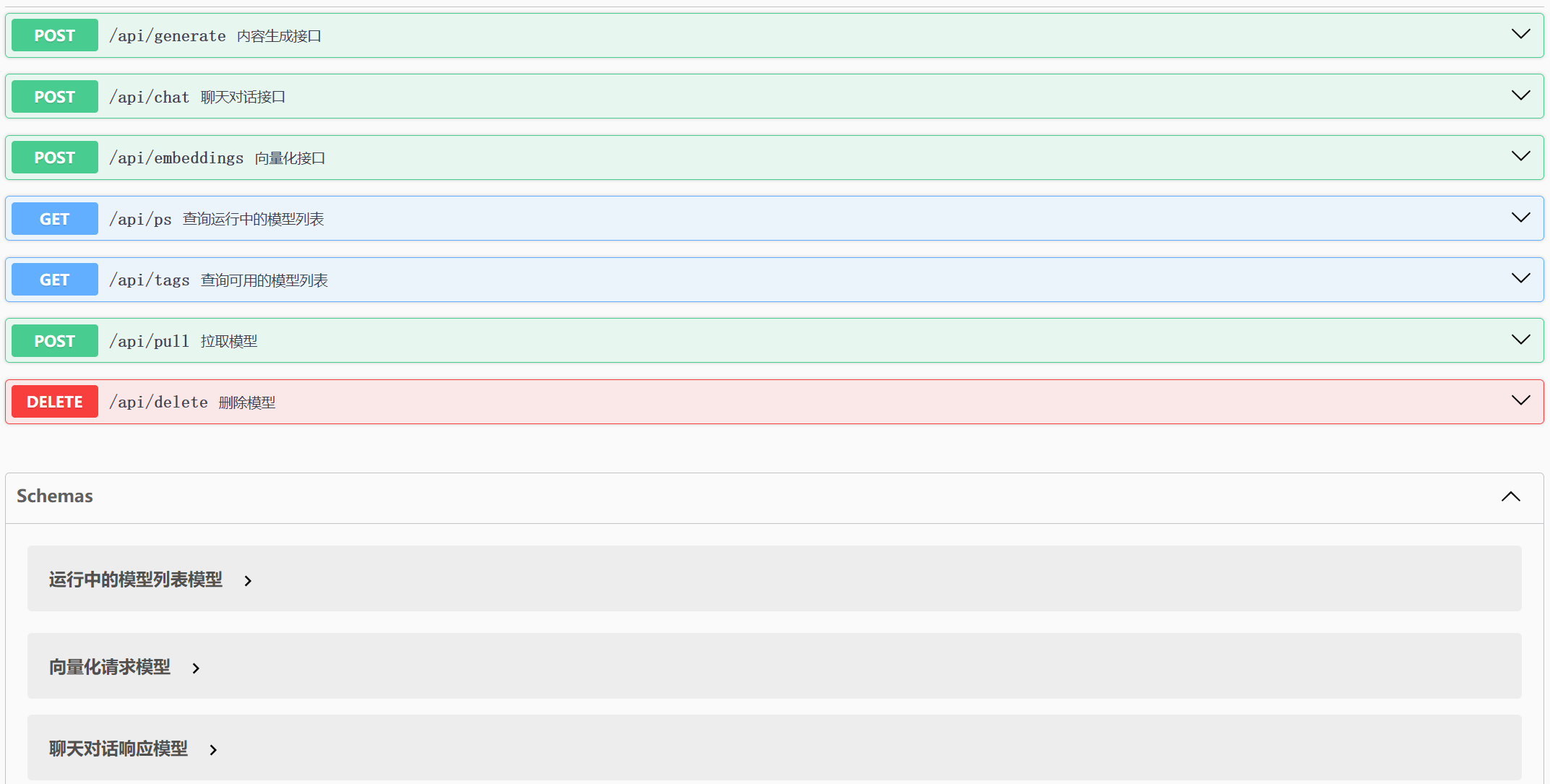
7.3 使用 Apifox 调试 API
Apifox 是一款集成了 API 文档、调试、Mock、自动化测试于一体的协同工作平台(Postman + Swagger + Mock.js + JMeter)。
官网:https://apifox.com/
安装与导入步骤:
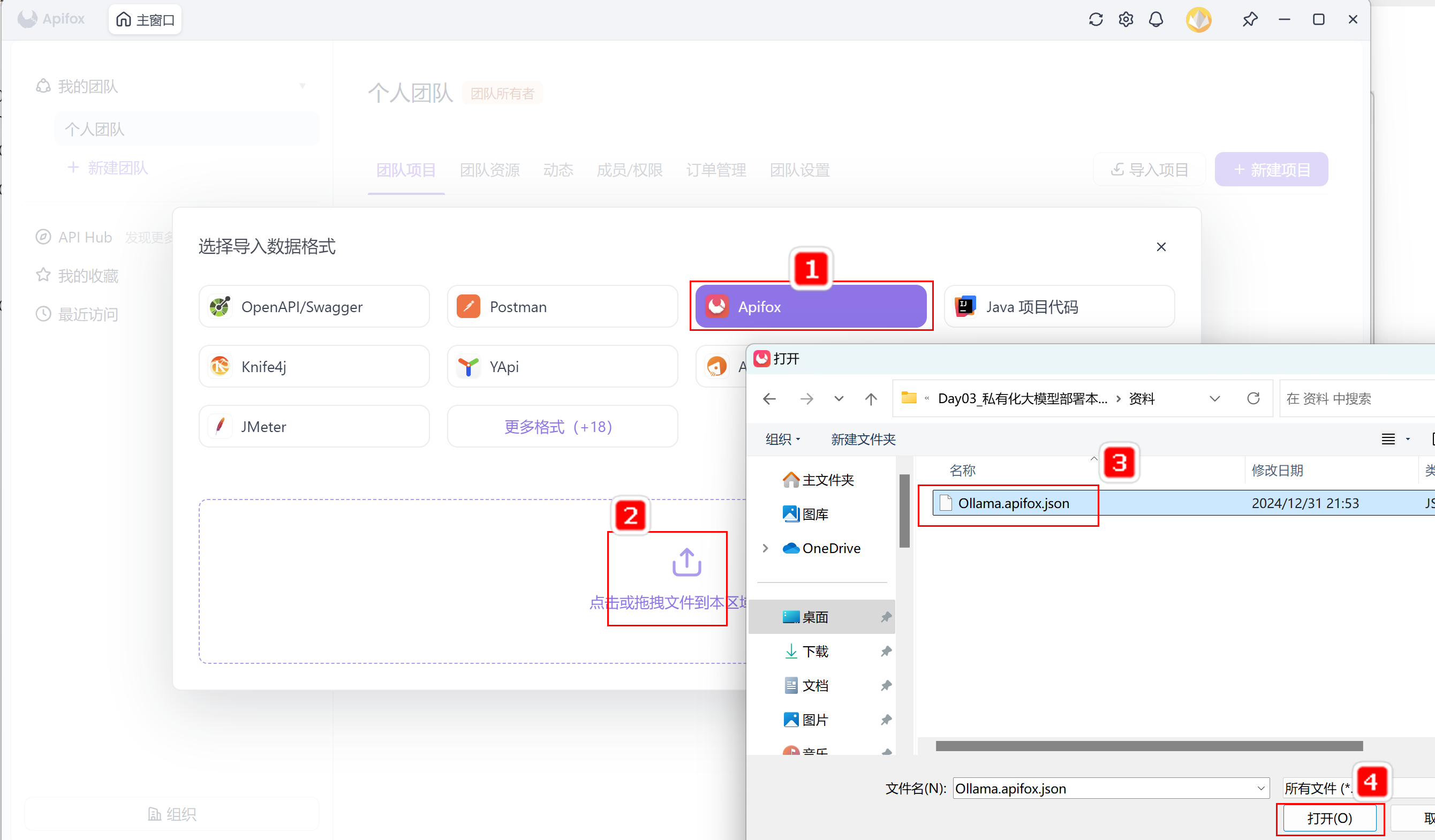
- 下载安装 Apifox
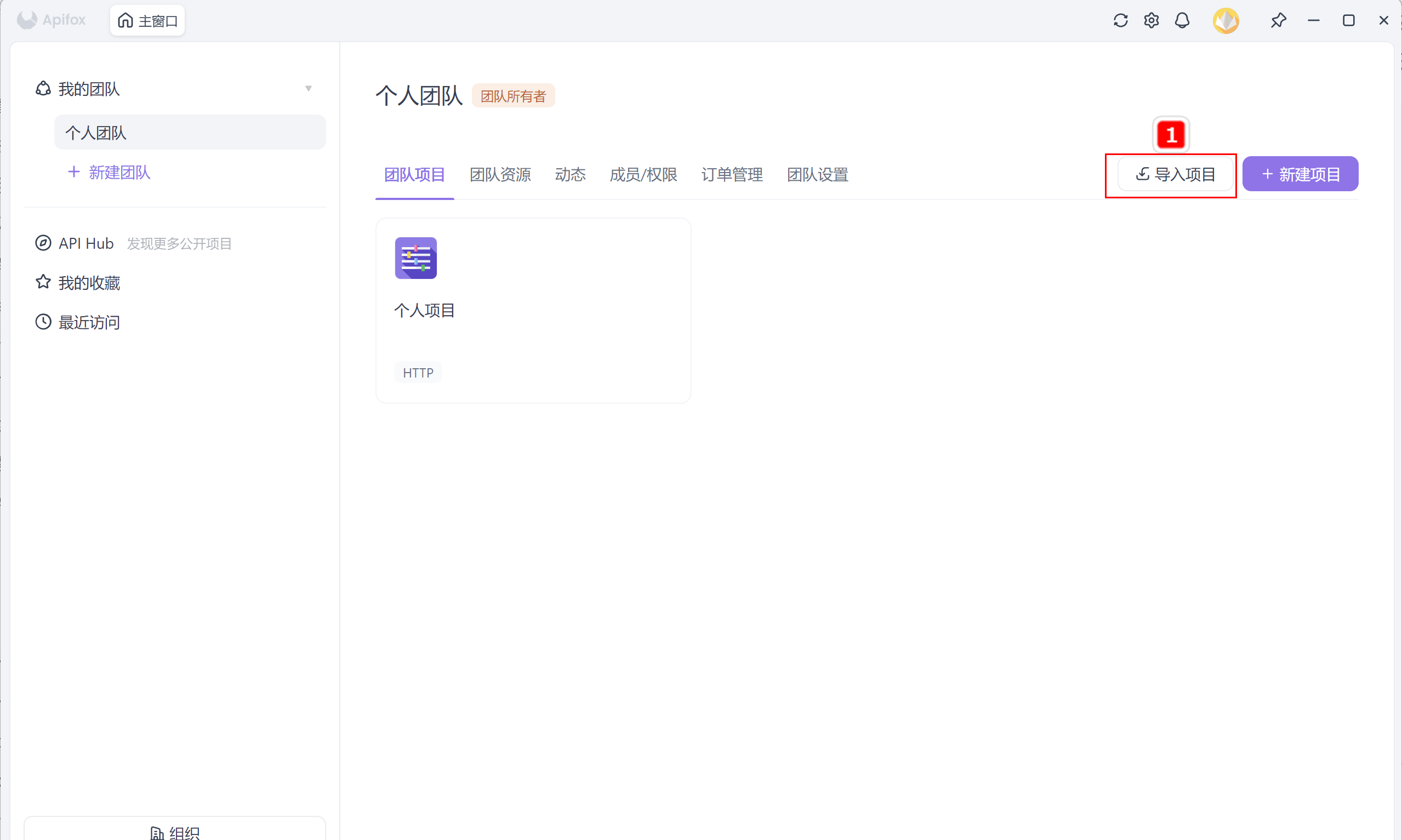
- 打开 Apifox,点击【导入项目】
- 选择导入格式(Apifox),选择
Ollama.apifox.json文件
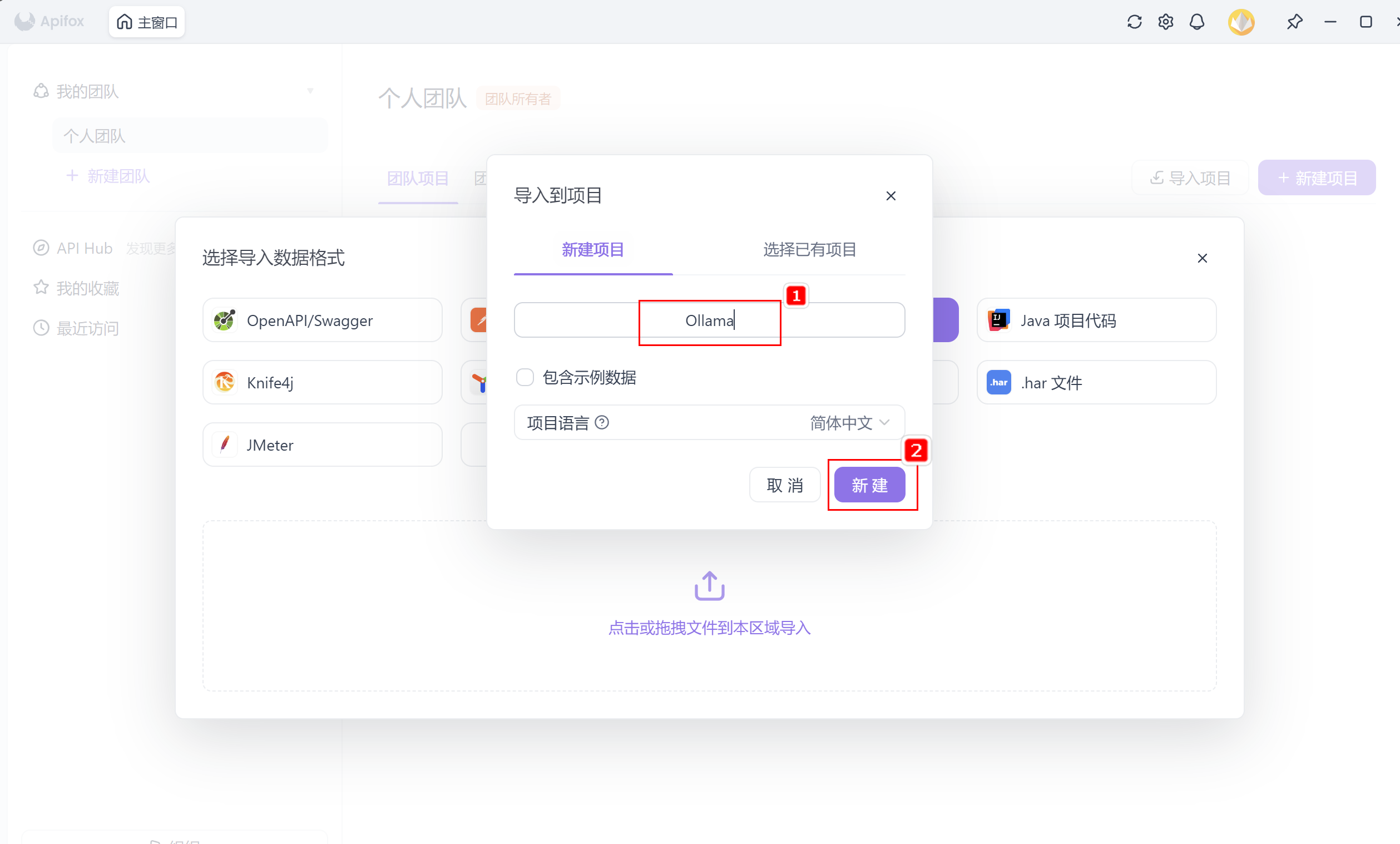
- 输入项目名称(如 "Ollama"),点击新建
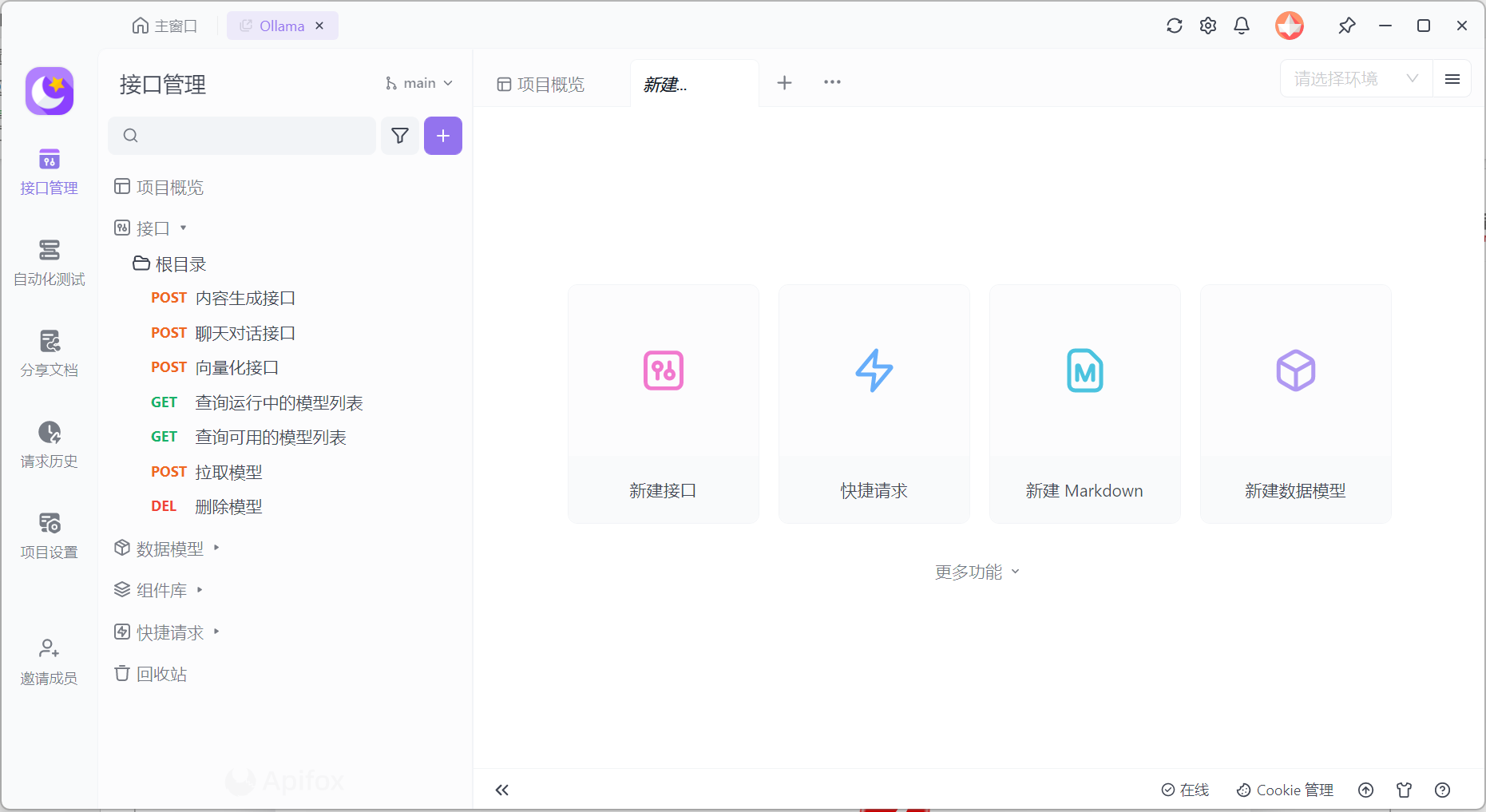
- 完成导入,进入项目查看接口列表
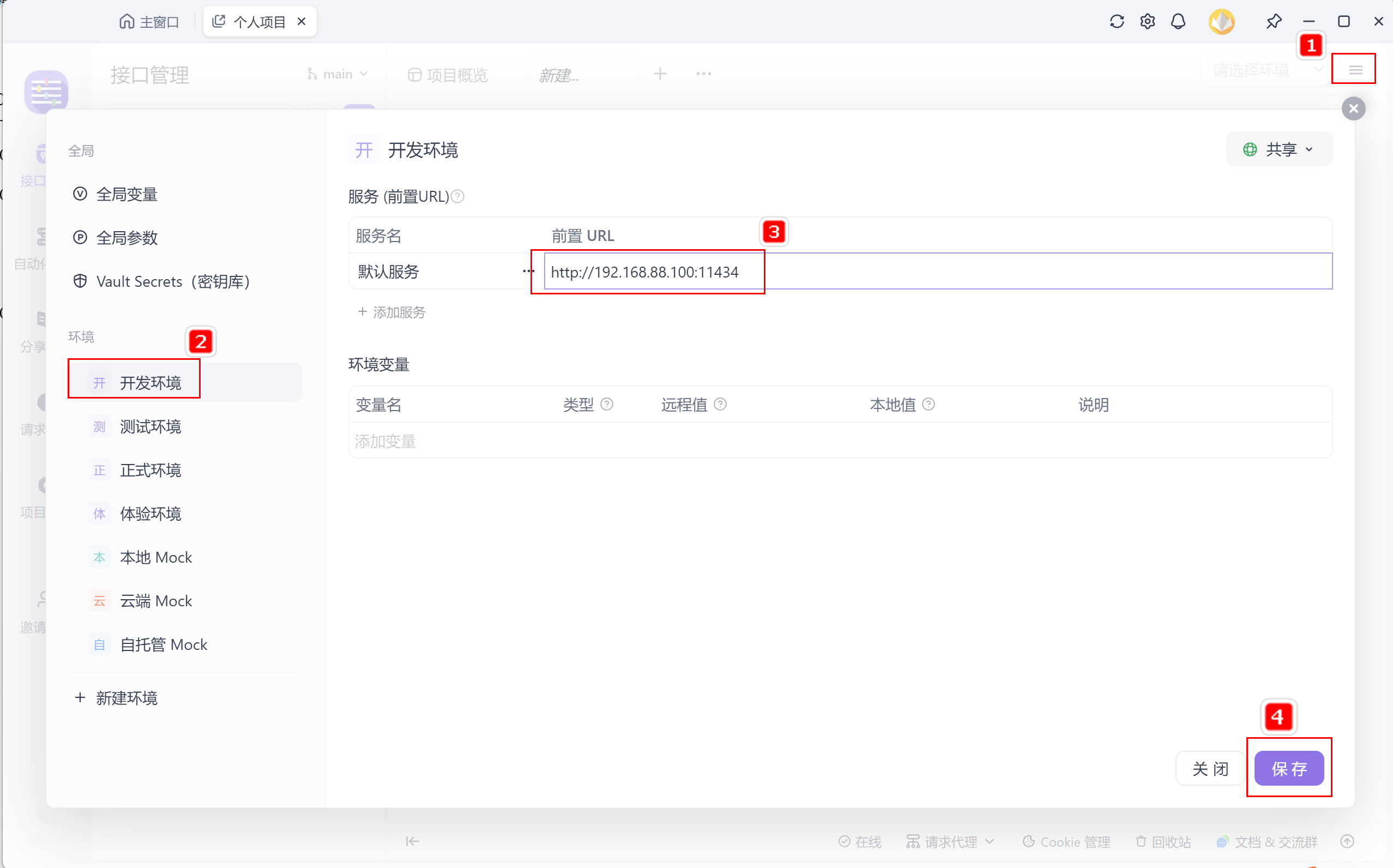
7.4 配置环境地址
在 Apifox 中配置测试环境:
- 前置 URL:http://127.0.0.1:11434(本地)或 http://<远程IP>:11434
7.5 聊天对话 API 详解
请求地址:POST /api/chat
请求参数:
| 参数 | 类型 | 必选 | 说明 |
|---|---|---|---|
| model | string | 是 | 模型名称(本地已下载) |
| messages | array | 是 | 聊天消息数组 |
| role | string | 是 | 角色:system、user、assistant |
| content | string | 是 | 消息内容 |
| images | string | 否 | 图像(多模态时使用) |
| format | string | 否 | 响应格式(如 json) |
| stream | boolean | 否 | 是否流式生成(默认 true) |
| keep_alive | string | 否 | 模型内存保持时间(如 5m) |
| options | object | 否 | 配置参数(temperature、top_k 等) |
请求体示例:
{
"model": "qwen2:1.5b",
"messages": [
{
"role": "user",
"content": "请讲一个程序员笑话"
}
],
"stream": false,
"options": {
"temperature": 0.7
}
}
返回示例:
{
"model": "qwen2:1.5b",
"created_at": "2024-09-07T09:00:57.035084368Z",
"message": {
"role": "assistant",
"content": "当然可以!这是一个程序员笑话:..."
},
"done": true,
"total_duration": 14452649821,
"load_duration": 21370256,
"prompt_eval_count": 213,
"prompt_eval_duration": 11306354000,
"eval_count": 25,
"eval_duration": 3082983000
}
7.6 实际调用示例
在 Apifox 中配置请求:
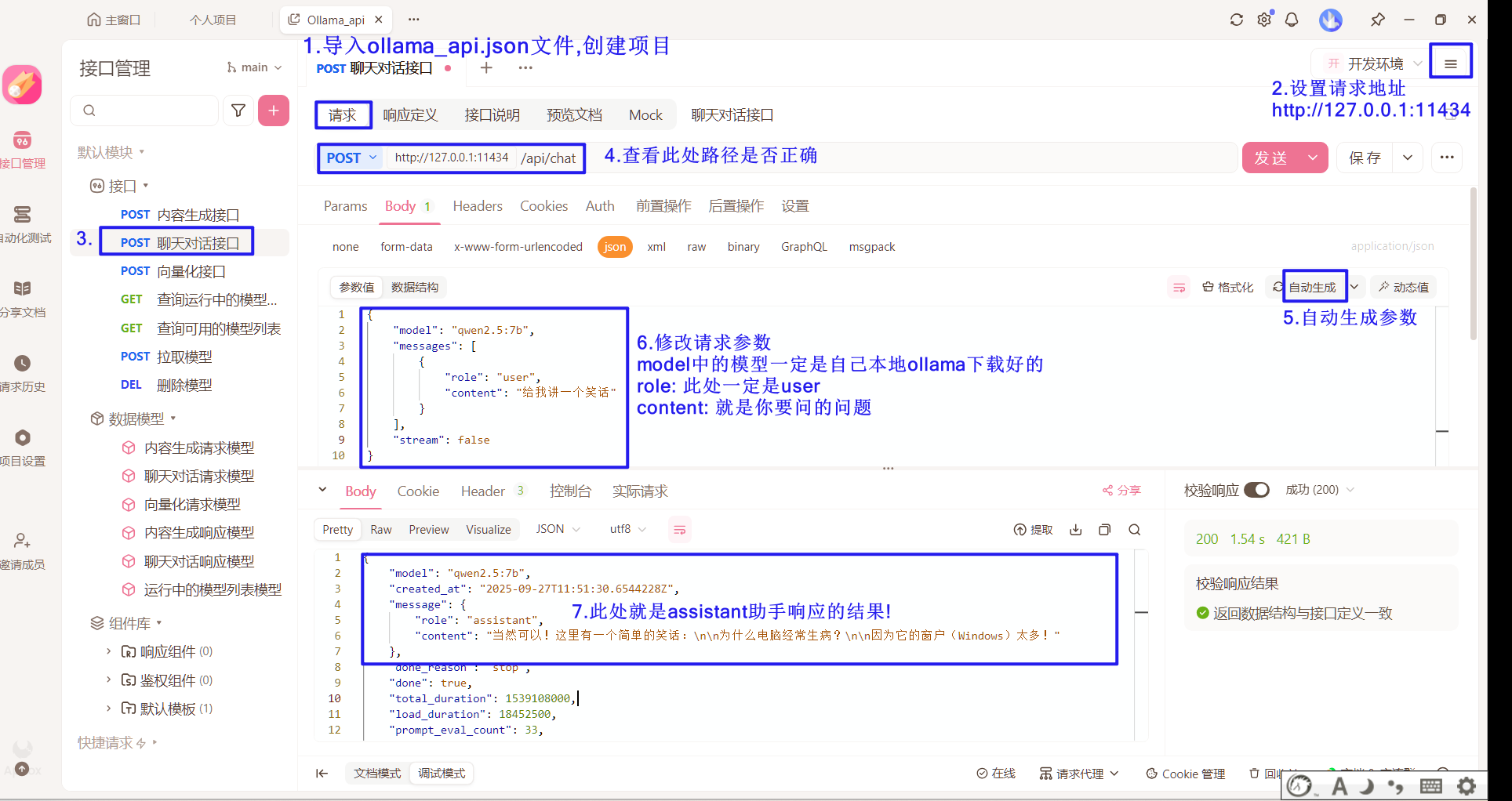
关键点:
- model 中的模型必须是你本地 Ollama 已下载好的
- role 此处一定是 user
- content 就是你要问的问题
- 响应结果中 message.content 就是助手(assistant)的回答
八、搭建你的私有 ChatBot:ChatBox + Ollama
命令行对话虽然高效,但不够直观。通过 ChatBox 这款开源客户端,你可以为 Ollama 套上一个类似 ChatGPT 的精美界面。
8.1 ChatBox 简介
ChatBox 是一款支持多平台(Windows、macOS、Linux、iOS、Android)的 AI 客户端,支持接入 OpenAI、Claude、Ollama 等多种模型。
功能特点: - 一键免费拥有你自己的 ChatGPT / Gemini / Claude / Ollama 应用 - 与文档和图片聊天 - 代码生成与预览 - 支持本地大模型 - 支持多平台 AI 接入 - 支持插件扩展
8.2 安装 ChatBox
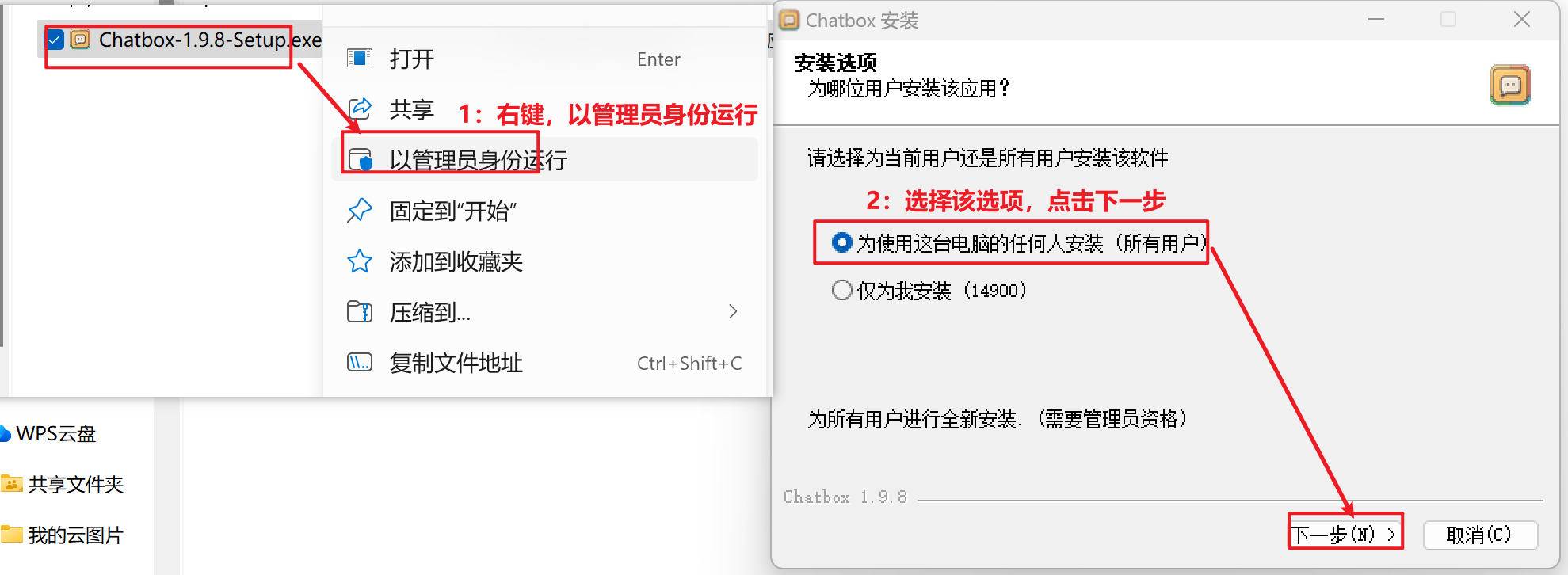
下载安装包(如 Chatbox-1.9.8-Setup.exe),右键以管理员身份运行:
8.3 ChatBox 主界面
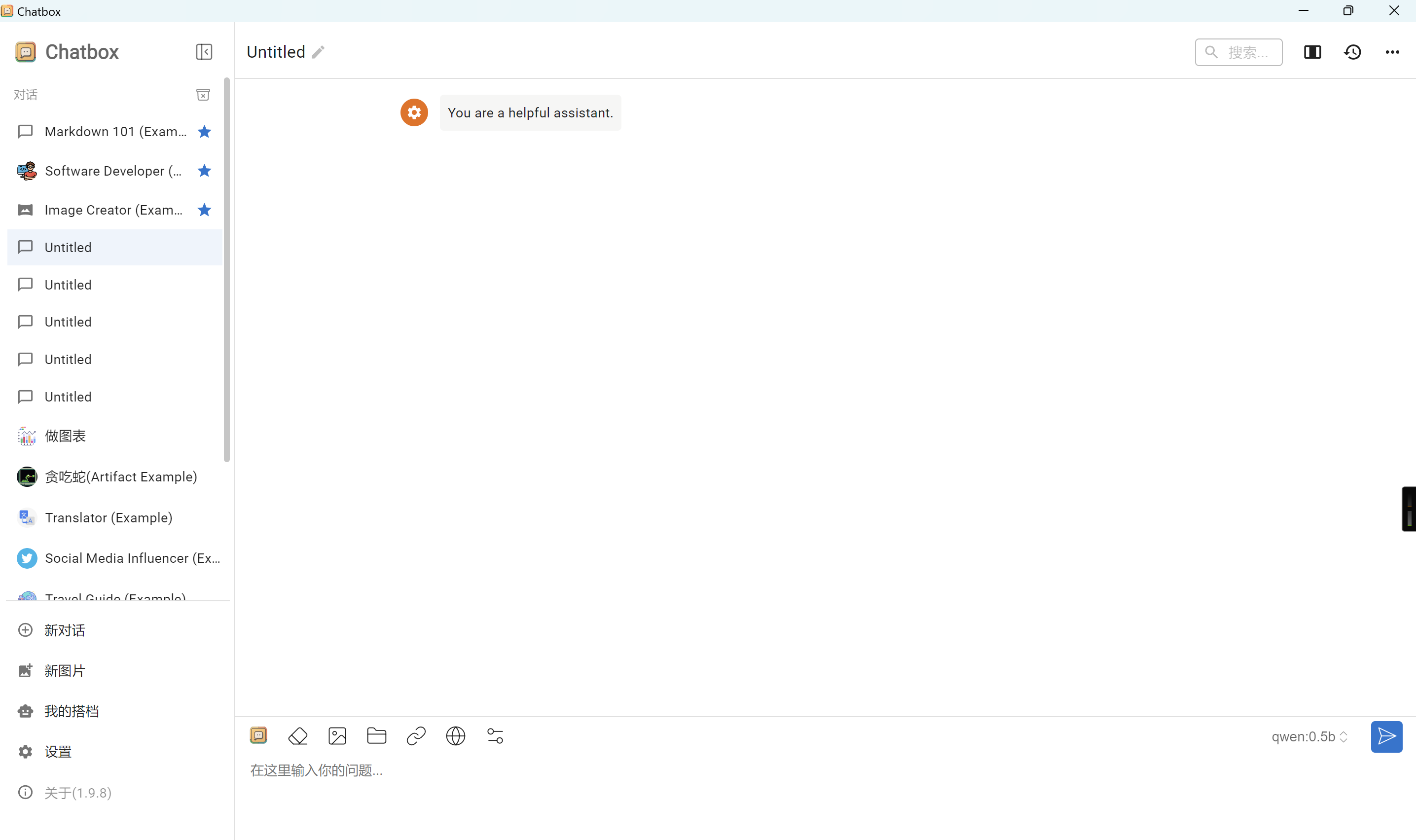
安装完成后打开软件,主界面包括: - 左侧:功能菜单、对话历史列表 - 右侧:对话互动界面、输入框、模型选择
8.4 连接 Ollama 与 ChatBox
配置步骤:
- 进入软件后,点击左下角【设置】
- 模型提供方选择:OLLAMA API
- API 域名填写:
http://127.0.0.1:11434(如果是远程服务器,填写对应 IP) - 模型选择:下拉框会自动读取你本地已下载的 Ollama 模型
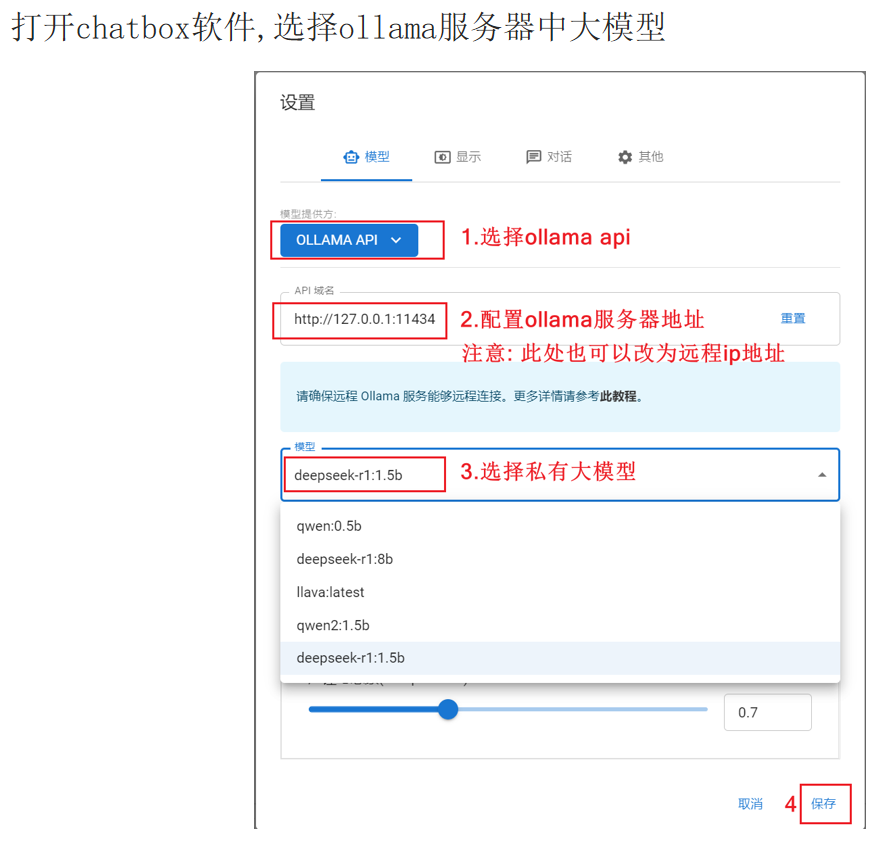
- 保存配置,返回对话界面
8.5 开始对话
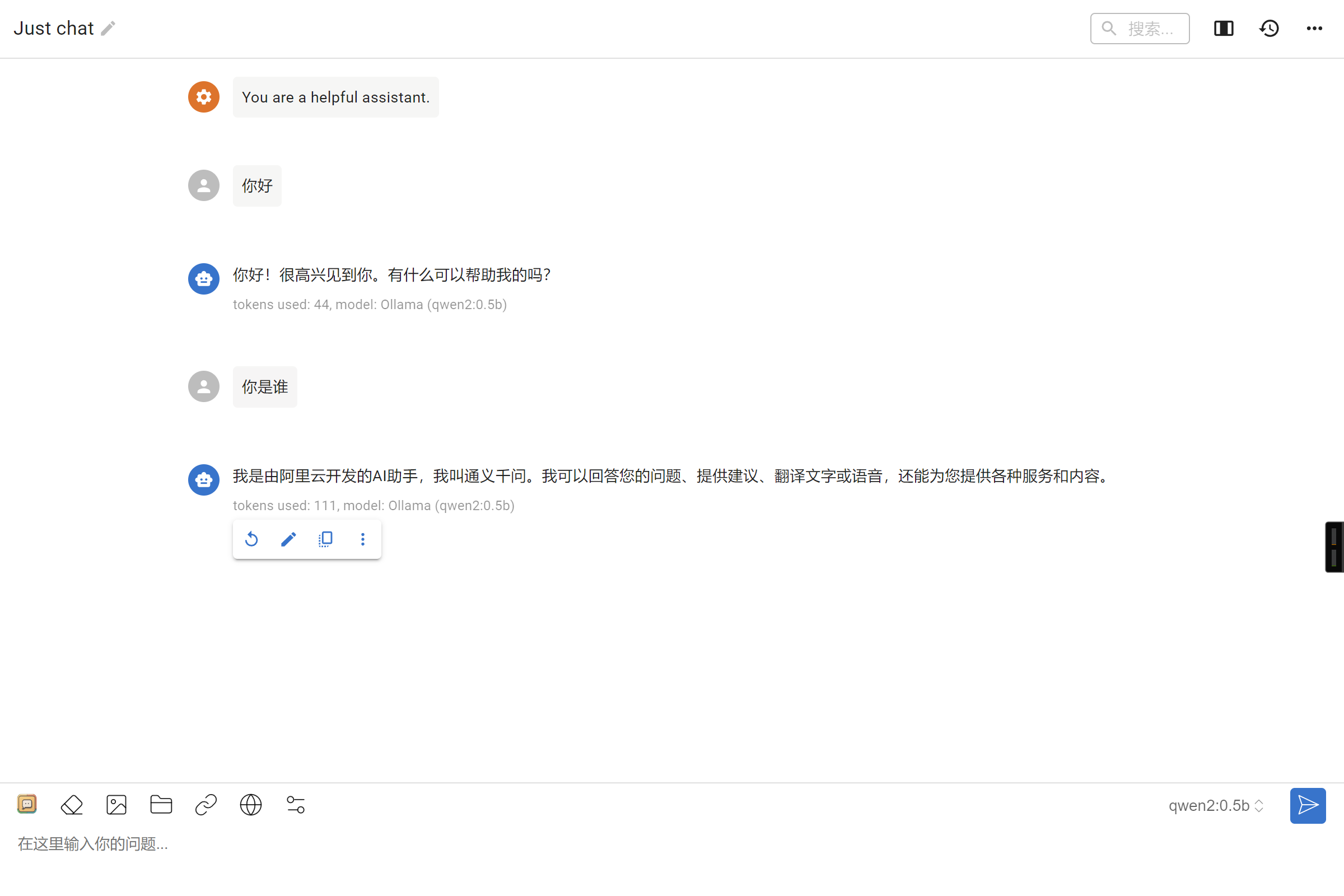
配置完成后,在底部输入框输入问题,即可与本地大模型进行对话:
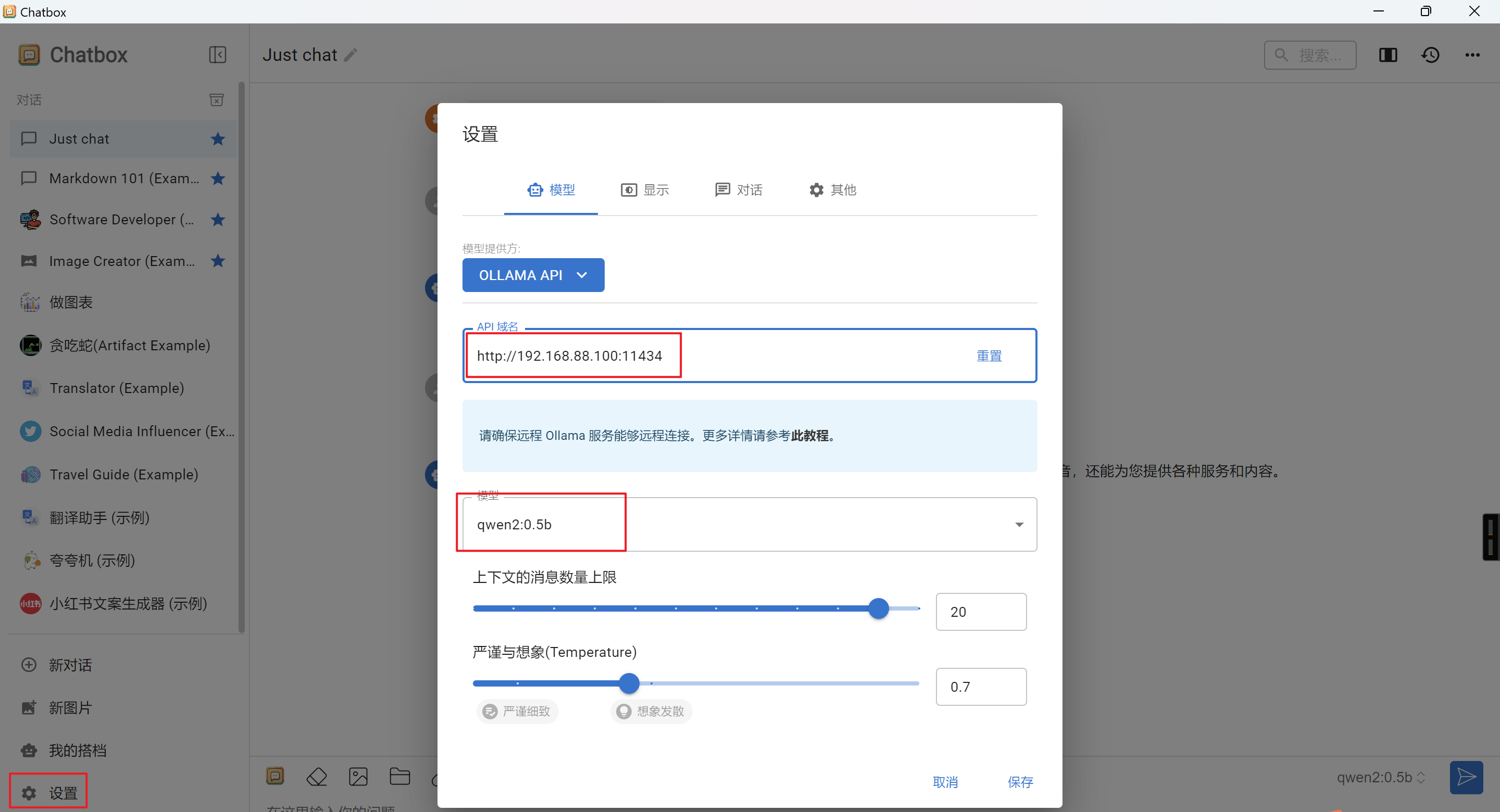
远程连接配置:
如果 Ollama 部署在远程服务器上,在 ChatBox 中配置远程 IP 地址即可:
九、总结与学习路径
通过本文,我们完成了从大模型概念认知到私有化部署落地的完整闭环:
- 认知层:理解了大模型的分类(NLP/CV/语音/多模态)及应用场景
- 决策层:明确了私有化部署的必要性(安全、可控、低成本)
- 工具层:选择 Ollama 作为轻量化本地运行框架
- 实战层:完成安装、模型部署、命令管理、API 调用
- 应用层:通过 ChatBox 搭建可视化私有 ChatBot
下一步建议:
- 尝试使用 Modelfile 自定义系统提示词,打造专属角色助手
- 学习使用 /api/embeddings 接口,结合向量数据库搭建本地知识库(RAG)
- 探索多模态模型(如 llava),让本地模型具备图像理解能力
私有化大模型的门槛正在迅速降低,现在就是入场的最佳时机。
附录:Ollama 常用模型推荐(轻量版)
| 模型 | 参数规模 | 特点 | 适用场景 |
|---|---|---|---|
deepseek-r1:1.5b |
1.5B | 推理能力强 | 逻辑分析、代码辅助 |
qwen2:1.5b |
1.5B | 中文优化好 | 日常对话、文案生成 |
gemma3:1b |
1B | Google出品,轻量高效 | 低配置设备、快速响应 |
llava:latest |
- | 多模态支持 | 图像理解、图文对话 |